Introduction to Jupyter Notebooks¶
Jupyter Notebook is open-source software created and maintained by the Jupyter community. A Jupyter notebook allows for the creation and sharing of documents with code and rich text elements. It works with over 40 programming languages including Python, R, and Ruby making it versatile and flexible for data scientists. In this introductory blog to Jupyter notebooks, we will look at "why it exists" and "what it looks like".
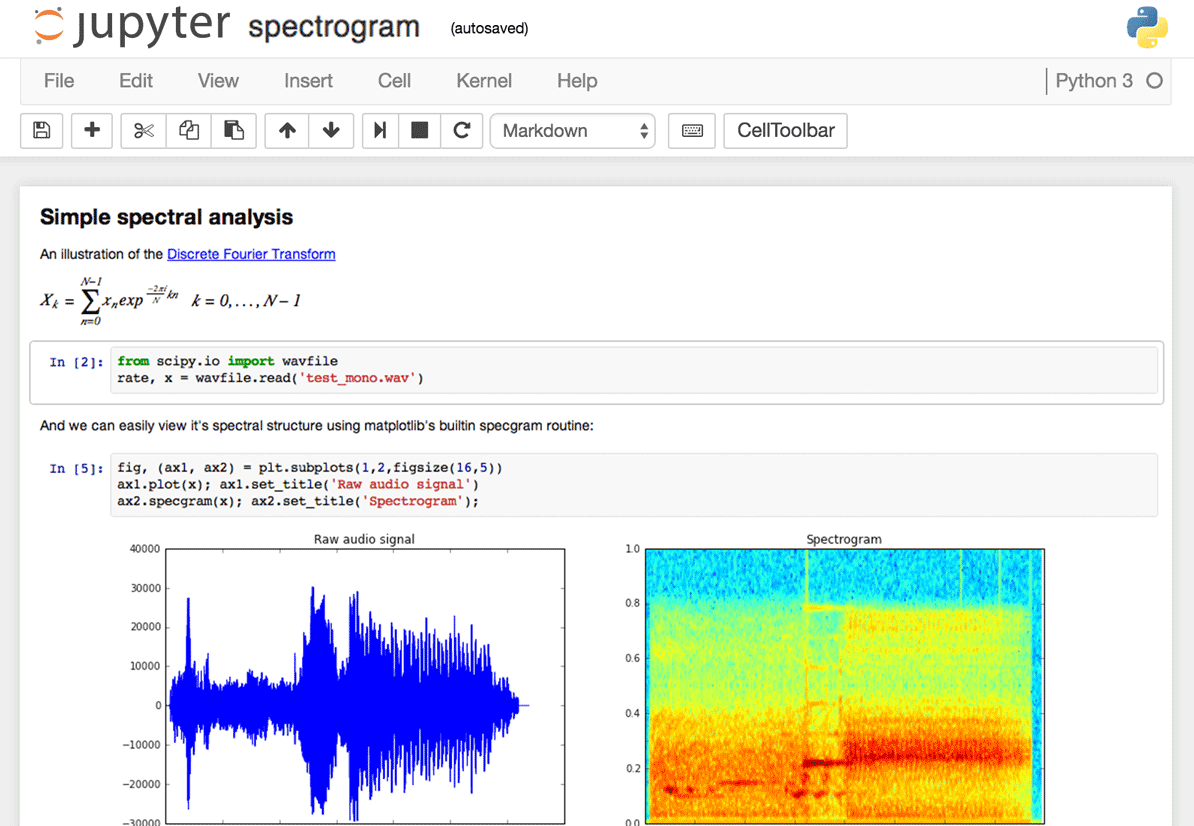
Why Does it Exist?¶
For traditional software developers, Jupyter notebooks may look very strange especially when you see the mix of code, text and graphics in the same file. Source code is more often read than written. So, having the text and charts can be critical to help describe why certain decisions were made. The source data is what shapes your data analysis code. But, lack of context can make it extremely hard to read. Here are some examples:
- Why are we joining these two tables?
- Why did we remove observations with values >10?
Why Not Use Comments?¶
Every programming language supports comments. Software developers use comments in their source code extensively to explain how their code works, assumptions etc. So, why can't data scientists use comments instead?.
While comments are useful, in most situations for data science, "tables" and "graphics" are needed to support decisions. These also serve as a record for others that data scientists collaborate with. What software developers frequently miss is that from the perspective of a data scientist, they are processing a dataset and are trying to understand the dataset by exploring it.
The focus is on the data and not on the code.
Data science, statistical modeling, etc. requires a lot of explanation and illustration as to what assumptions are being made about the data, why you chose one model over another etc. This is really easy to achieve in a Jupyter notebook. When the data scientist arrives at something useable, they take the parts of the notebook that they wish to implement and export it into a Python file.
During the exploratory phase, iteration speed is more critical for data scientists than correctness. The entire notebook can be run again like a typical program to get more reproducible behavior.
What does it look like?¶
Jupyter notebooks can contain the results and figures in human readable form as well as computer code for executing data analysis. Typical data scientists use the Jupyter notebook through a web browser or via an extension for their Integrated Development Environment (IDE). At its core, a Jupyter notebook is a JSON file with a .ipynb extension.
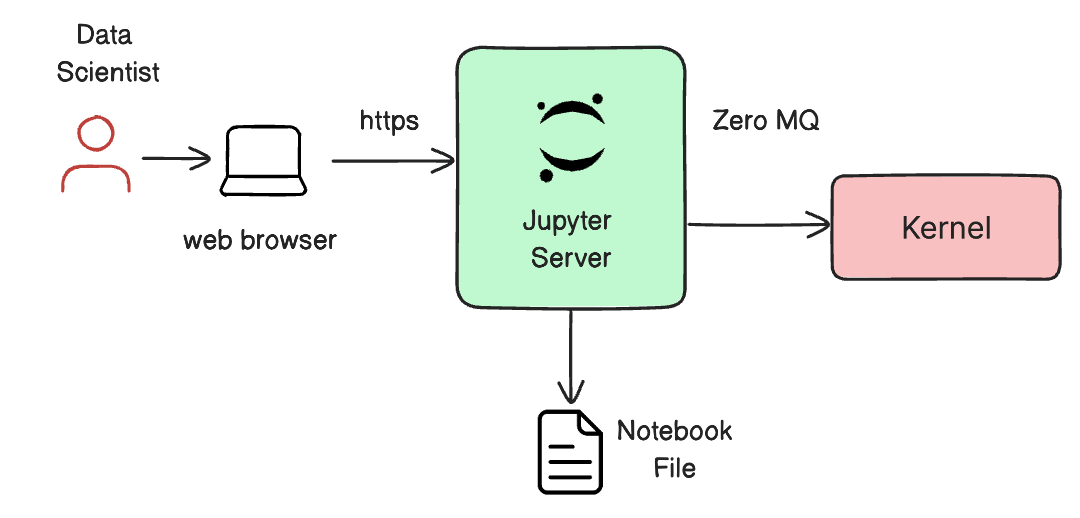
Web Browser¶
Data scientists typically utilize a web browser to access the Jupyter notebook.
Jupyter Server¶
The Jupyter server, not the kernel, is responsible for saving and loading notebooks. So it is possible to edit notebooks even if you do not have the right kernel for the language. You just cannot run that code.
The kernel doesn’t know anything about the notebook document itself. It is sent cells of code to execute when the user runs them. The code is then executed by the kernel before delivering the results.
Note
Each programming language has its own kernel that executes the code in the notebook document. There is a massive list of available kernels that can be used in a Jupyter notebook.
Issues with Standalone Jupyter Notebooks¶
Although data scientists can download, configure and use Jupyter notebooks on their laptops, this approach is not a very effective and scalable approach for organizations because
It requires every data scientist to become an expert on and perform the following:
- Spend time downloading and installing the correct versions of Python
- Create virtual environments, troubleshooting installs,
- Deal with system vs. non-system versions of Python,
- Install packages, dealing with folder organization
- Understand the difference between conda and pip,
- Learn various command-line commands
- Understand differences between Python on Windows vs macOS
On top of this, there are other limitations that will impact the productivity of data scientists as well.
- Being limited by the compute capabilities of the laptop i.e. no GPU etc
- Data scientists pursuing Shadow IT for use of compute resources from public clouds
- Constantly download and upload large sets of data
- Unable to access data because of corporate security policies.
- Unable to collaborate (share notebooks etc) with other data scientists effectively
Multi User, Collaborative Environments¶
In the next blog, we will look at how organizations can address all of these challenges by providing their data scientists a hosted, multi-user, collaborative environment for their Jupyter notebooks.
We will specifically look at JupyterHub which is a multi-user system that spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server. Organizations can use this to serve a variety of interfaces and environments on many kinds of infrastructure.
We will also look at how our customers use Rafay's template for JupyterHub to provide a highly performant and resilient service for their data scientists internally.
Blog Ideas¶
Sincere thanks to readers of our blog who spend time reading our product blogs. This blog was authored because we are working with several customers that are expanding their use of Jupyter notebooks on Kubernetes and AWS Sagemaker using the Rafay Platform. Please contact us if you would like us to write about other topics.