Part 3: Blueprint
What Will You Do¶
In this part of the self-paced exercise, you will create a custom cluster blueprint with Nvidia's GPU Operator based on declarative specifications.
Step 1: GPU Operator Repository¶
Nvidia distributes their GPU Operator software via their official Helm repository. In this step, you will create a repository in your project so that the controller can retrieve the Helm charts automatically.
- Open Terminal (on macOS/Linux) or Command Prompt (Windows) and navigate to the folder where you forked the Git repository
- Navigate to the folder "
/getstarted/gpueks/addon"
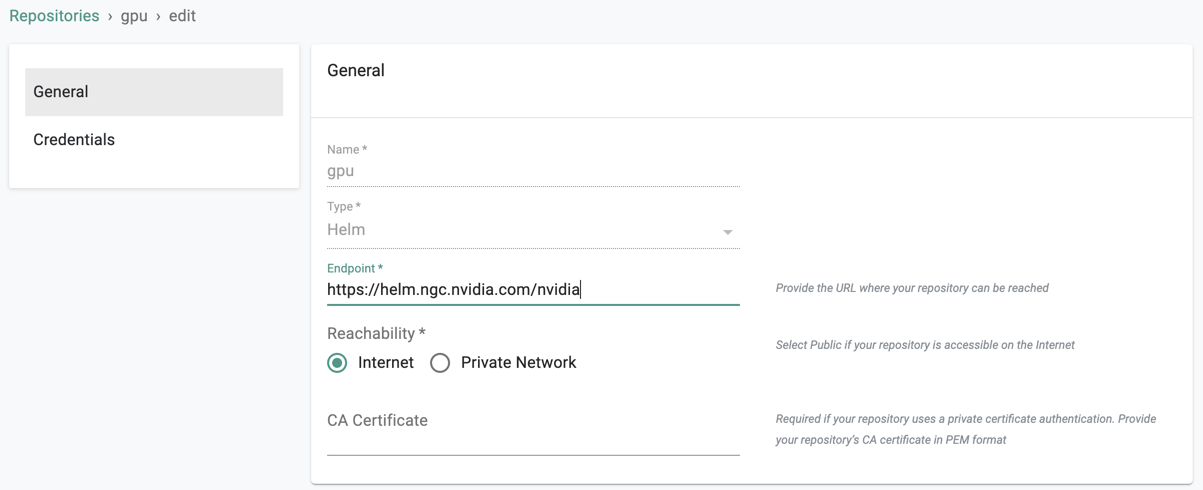
The "repository.yaml" file contains the declarative specification for the repository. In this case, the specification is of type "Helm Repository" and the "endpoint" is pointing to Nvidia's official Helm repository.
apiVersion: config.rafay.dev/v2
kind: Repository
metadata:
name: gpu
spec:
repositoryType: HelmRepository
endpoint: https://helm.ngc.nvidia.com/nvidia
credentialType: CredentialTypeNotSet
Type the command below
rctl create repository -f repository.yaml
If you did not encounter any errors, you can optionally verify if everything was created correctly on the controller.
- Navigate to your Org and Project
- Select Integrations -> Repositories and click on "gpu"
Step 2: Create Namespace¶
In this step, you will create a namespace for the Nvidia GPU Operator. The "namespace.yaml" file contains the declarative specification
The following items may need to be updated/customized if you made changes to these or used alternate names.
- value: demo-gpu-eks
kind: ManagedNamespace
apiVersion: config.rafay.dev/v2
metadata:
name: gpu-operator-resources
description: namespace for gpu-operator
labels:
annotations:
spec:
type: RafayWizard
resourceQuota:
placement:
placementType: ClusterSpecific
clusterLabels:
- key: rafay.dev/clusterName
value: demo-gpu-eks
- Open Terminal (on macOS/Linux) or Command Prompt (Windows) and navigate to the folder where you forked the Git repository
- Navigate to the folder "
/getstarted/gpueks/addon" - Type the command below
rctl create namespace -f namespace.yaml
If you did not encounter any errors, you can optionally verify if everything was created correctly on the controller.
- Navigate to the "defaultproject" project in your Org
- Select Infrastructure -> Namespaces
- You should see a namespace called "gpu-operator-resources"

Step 3: Create Addon¶
In this step, you will create a custom addon for the Nvidia GPU Operator. The "addon.yaml" file contains the declarative specification
- "v1" because this is our first version
- Name of addon is "gpu-operator"
- The addon will be deployed to a namespace called "gpu-operator-resources"
- You will be using "v23.3.1" of the Nvidia GPU Operator Helm chart
- You will be using a custom "values.yaml as an override
kind: AddonVersion
metadata:
name: v1
project: defaultproject
spec:
addon: gpu-operator
namespace: gpu-operator-resources
template:
type: Helm3
valuesFile: values.yaml
repository_ref: gpu
repo_artifact_meta:
helm:
tag: v23.3.1
chartName: gpu-operator
Type the command below
rctl create addon version -f addon.yaml
If you did not encounter any errors, you can optionally verify if everything was created correctly on the controller.
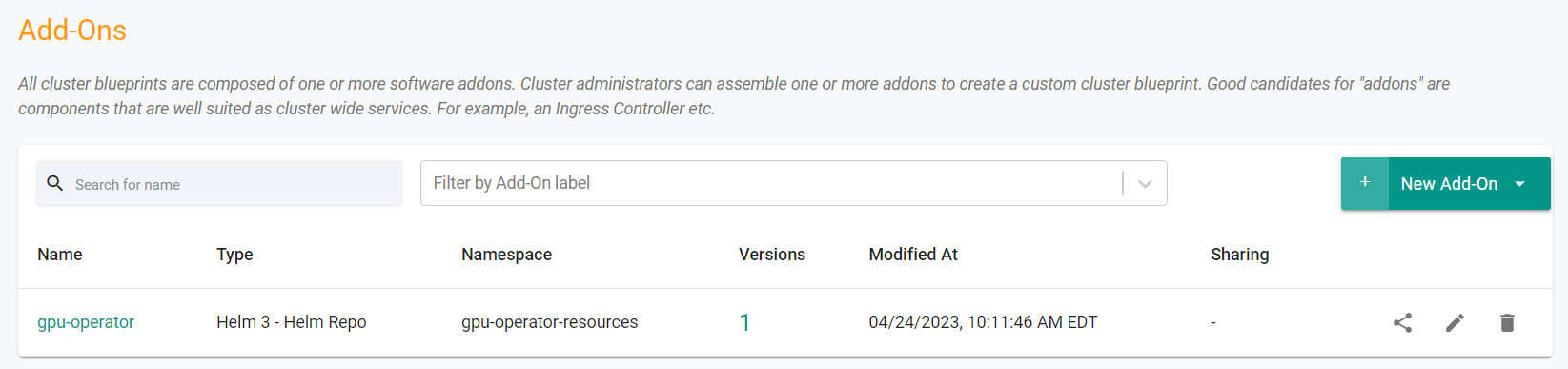
- Navigate to your Org and "Default" Project
- Select Infrastructure -> Addons
- You should see an addon called "gpu-operator
Step 4: Create Blueprint¶
In this step, you will create a custom cluster blueprint with the Nvidia GPU Operator and a number of other system addons. The "blueprint.yaml" file contains the declarative specification.
- Open Terminal (on macOS/Linux) or Command Prompt (Windows) and navigate to the folder where you forked the Git repository
- Navigate to the folder "
/getstarted/gpueks/blueprint"
kind: Blueprint
metadata:
# blueprint name
name: gpu-blueprint
#project name
project: defaultproject
- Type the command below
rctl create blueprint -f blueprint.yaml
If you did not encounter any errors, you can optionally verify if everything was created correctly on the controller.
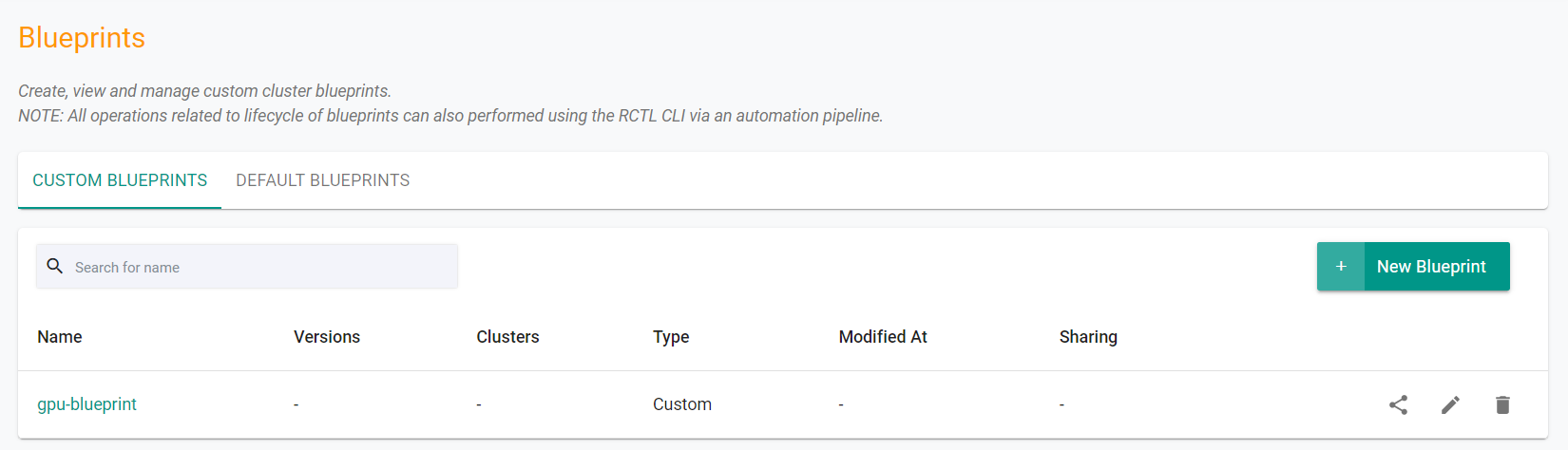
- Navigate to your Org -> defaultproject
- Select Infrastructure -> Blueprint
- You should see an blueprint called gpu-blueprint
New Version¶
Although we have a custom blueprint, we have not provided any details on what it comprises. In this step, you will create and add a new version to the custom blueprint. The YAML below is a declarative spec for the new version.
kind: BlueprintVersion
metadata:
name: v1
project: defaultproject
description: Nvidia GPU Operator
spec:
blueprint: gpu-blueprint
baseSystemBlueprint: default
baseSystemBlueprintVersion: ""
addons:
- name: gpu-operator
version: v1
# cluster-scoped or namespace-scoped
pspScope: cluster-scoped
rafayIngress: false
rafayMonitoringAndAlerting: true
# BlockAndNotify or DetectAndNotify
driftAction: BlockAndNotify
- Type the command below to add a new version
rctl create blueprint version -f blueprint-v1.yaml
If you did not encounter any errors, you can optionally verify if everything was created correctly on the controller.
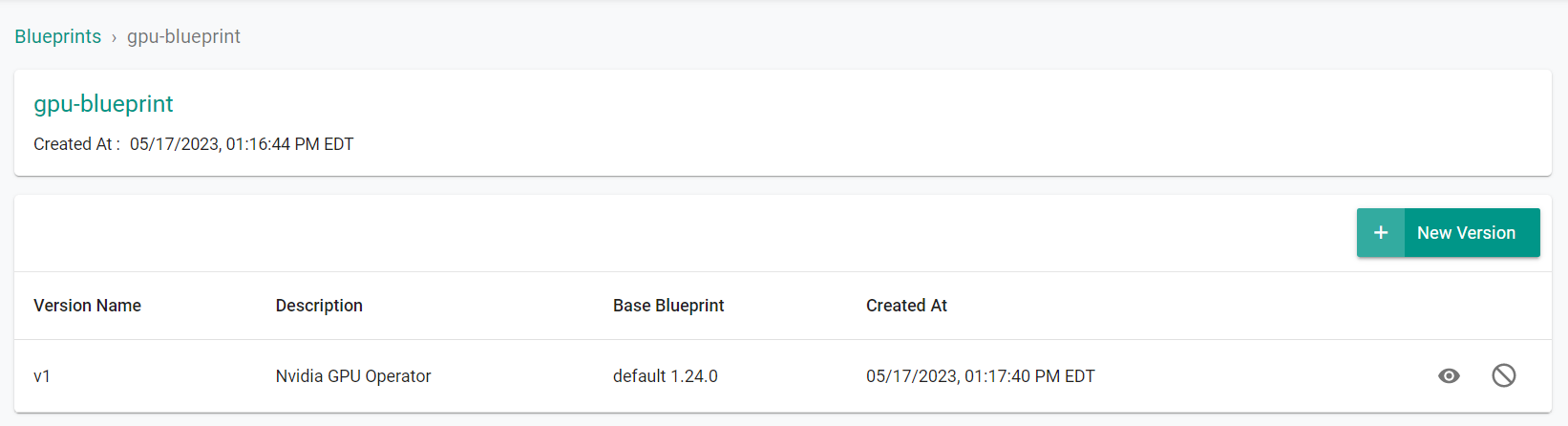
- Select Infrastructure -> Blueprint
- Click on the gpu-blueprint custom cluster blueprint
Step 5: Apply Blueprint¶
In this step, you will apply the custom blueprint with the GPU operator to the cluster.
Type the command below
rctl update cluster demo-gpu-eks --blueprint gpu-blueprint --blueprint-version v1
Step 4: Verify GPU Operator¶
Now, let us verify whether the Nvidia GPU Operator's resources are operational on the EKS cluster
- Click on the kubectl link and type the following command
kubectl get po -n gpu-operator-resources
You should see something like the following. Note, it could take ~7 minutes for all pods to become running.
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-6cb5r 1/1 Running 0 7m16s
gpu-operator-7f6d6fc8cf-7wt25 1/1 Running 0 8m17s
gpu-operator-node-feature-discovery-master-c4fd9d8cf-62pd4 1/1 Running 0 8m17s
gpu-operator-node-feature-discovery-worker-ckqzg 1/1 Running 0 8m17s
gpu-operator-node-feature-discovery-worker-x6vkc 1/1 Running 0 8m17s
nvidia-container-toolkit-daemonset-kcdks 1/1 Running 0 7m16s
nvidia-cuda-validator-w4f9t 0/1 Completed 0 63s
nvidia-dcgm-exporter-x9898 1/1 Running 0 7m16s
nvidia-device-plugin-daemonset-swtzx 1/1 Running 0 7m16s
nvidia-device-plugin-validator-264bq 0/1 Completed 0 46s
nvidia-driver-daemonset-2xs78 1/1 Running 0 8m
nvidia-operator-validator-4xd7t 1/1 Running 0 7m16s
Recap¶
As of this step, you have created a "cluster blueprint" with the GPU Operator as one of the addons and applied the blueprint to the cluster.
Note that you can also reuse this cluster blueprint for as many clusters as you require in this project and also share the blueprint with other projects.