These past few months, we've invested a lot of time as a team working to create a more seamless experience for our customer-facing product documentation. While we built a lot of content covering key functionality of the platform, one of the key questions that would arise from our readers was how do I know where to start?
Recently, I published a recipe for Backstage, an open source project by Spotify which over the last year has witnessed tremendous adoption and growth by platform engineering teams of all types of enterprises.
Some of the key features of Backstage include:
an easy-to-use interface for developers
extensible plugin ecosystem (for ex. plugins available for GitHub Actions, ArgoCD, AWS, and more)
ability to easily build and publish tech documentation
native Kubernetes plugin for cloud-native apps
ability to compose different developer workflows into an Internal Developer Portal (IDP)
We have been running a number of internal and external (with partners/customers) enablement sessions over the last few weeks to provide "hands-on, labs based training" on some recently introduced capabilities in the Rafay Kubernetes Operations Platform.
Here's what we setup for those enablement sessions:
Each attendee was provided with their own Kubernetes cluster
We spun up ~25 "ephemeral" Kubernetes clusters on Digital Ocean (for life of the session)
We needed the clusters to be provisioned in just a few minutes for the training exercise
Each attendee had their own dedicated "Project" in the Rafay Org
A question that we frequently got asked after those enablement sessions was "I would love to run similar sessions with my extended team, how much did it cost to run those clusters?".
Our total spend for ~25 ephemeral clusters on Digital Ocean for these enablement sessions was less than $15. It was no wonder there has been so much interest in this.
We decided that it would help everyone if we shared the automation scripts and the methodology we have been using to provision Digital Ocean clusters and to import them to Rafay's platform here.
Around three years back, we noticed many of our customers struggling with enterprise wide standardization of their Kubernetes clusters. Every cluster in their Organization was a snowflake and they were looking for a way to enforce that every cluster had a "baseline set of add-ons". This prompted us to develop Cluster Blueprints which has turned out to be one of the most heavily used features in our platform.
In this blog, we will describe a superpower setting in the cluster blueprints feature that we see customers use heavily for their production clusters to secure against unplanned drift.
Some of the key questions that platform teams have to think about very early on in their K8s journey are:
How many clusters should I have? What is the right number for my organization?
Should I set up dedicated or shared clusters for my application teams?
What are the governance controls that need to be in place?
The model that customers are increasingly adopting is to standardize on shared clusters as the default and create a dedicated cluster only when certain considerations are met.
graph LR
A[Request for compute from Application teams] --> B[Evaluate against list of considerations] --> C[Dedicated or shared clusters];
A few example scenarios for which Platform teams often end up setting up dedicated clusters are:
Application has low latency requirements (target SLA/SLO is significantly different from others)
Application has specific requirements that are unique to it (e.g. GPU worker nodes, CNI plugin)
Based on Type of environment - ‘Prod’ has a dedicated clusters and 'Dev', 'Test' environments have shared clusters
With shared clusters (which is the most cost efficient and therefore the default model in most customer environments), there are certain challenges that platform teams have to solve for around security and operational efficiencies.
Earlier this year, AWS added support for Kubernetes v1.23 for their Amazon EKS offering. One significant change with this version is with the Container Storage Interface (CSI) for working with AWS Elastic Block Store (Amazon EBS) volumes.
Specifically, the updates to the CSI driver require customers to take action to ensure a seamless upgrade process for EKS clusters from previous versions. The CSI was developed in Kubernetes to replace the in-tree driver. With the CSI, there is now a simplified plug-in model that makes it easier for storage providers to decouple their releases from the Kubernetes release cycle.
graph LR
A[In-Tree Storage Driver] --> B[CSI Plugin for EBS CSI];
In a nutshell, this transition is good for Amazon EKS users because they do not have to upgrade Kubernetes versions for their EKS clusters just to get some additional functionality or bug fixes for EBS storage via the "in-tree driver".
Are you an App Developer struggling to learn the basics of Kubernetes because you have no time and no access to resources that help you with this in a step-by-step manner?
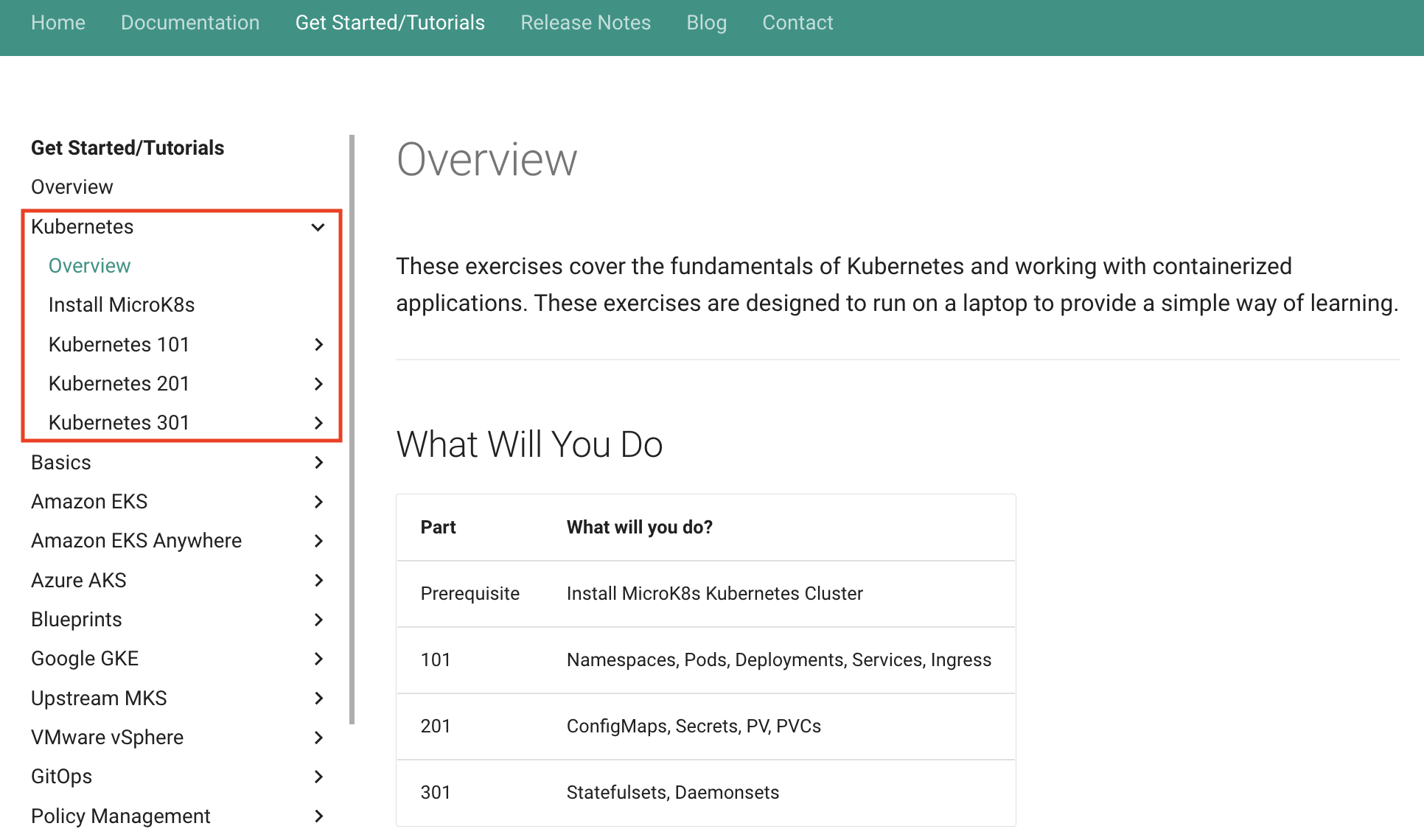
We invest a lot of time creating and maintaining our customer facing product documentation. Over the last few years, as we added significant width to our platform, we found ourselves in a situation where the way the content was presented especially for new users was overwhelming to them.
We have been working behind the scenes for a few weeks to present the breadth of capabilities of the platform in our documentation in a format that is "visually easy" for the user to navigate. Today, we launched our refreshed Product Documentation site. We thought it would be fun to memorialize this milestone by writing a brief blog.
We invest a lot of time training our employees, partners and customers on capabilities that are seeing a lot of inbound interest from our customers.
Earlier this week, we provided "hands-on, labs based training" for approximately 30 technologists on a very interesting "capability" in the Rafay Kubernetes Operations Platform.
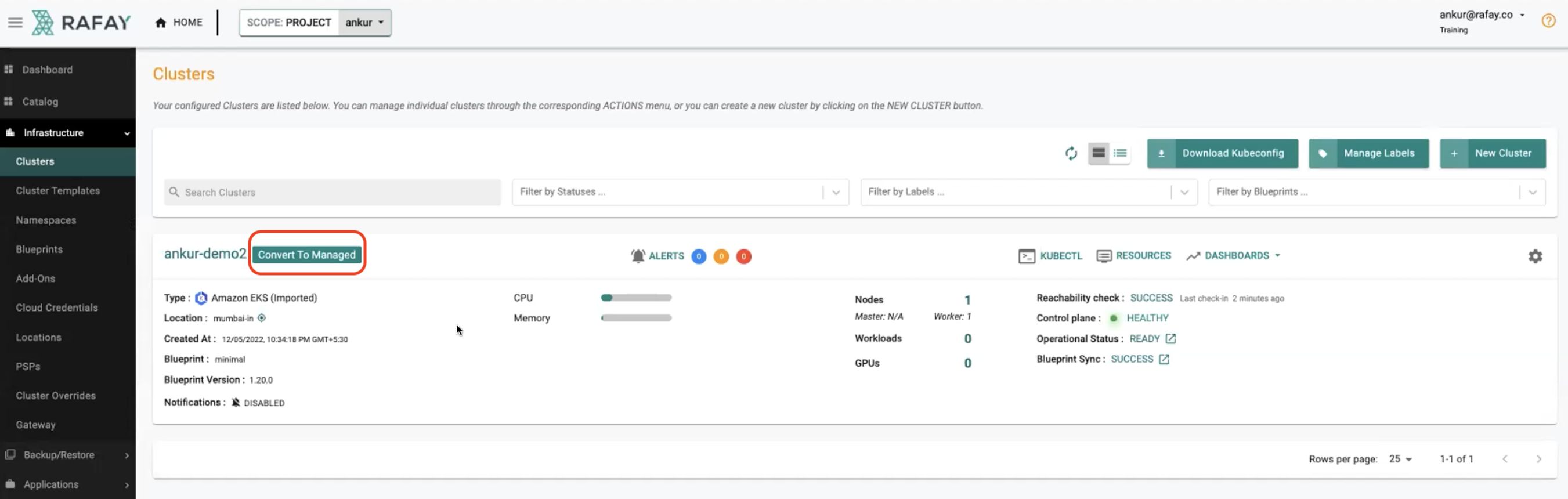
Many of our customers that use AWS typically already have a few Amazon EKS clusters provisioned and in use before they intercept with the Rafay Kubernetes platform.
They may have provisioned these clusters using Terraform or one of the many alternatives that exist in the market.
As they start using the platform, they naturally stumble onto the "Convert to Managed" option next to their imported EKS clusters and learn about this capability.
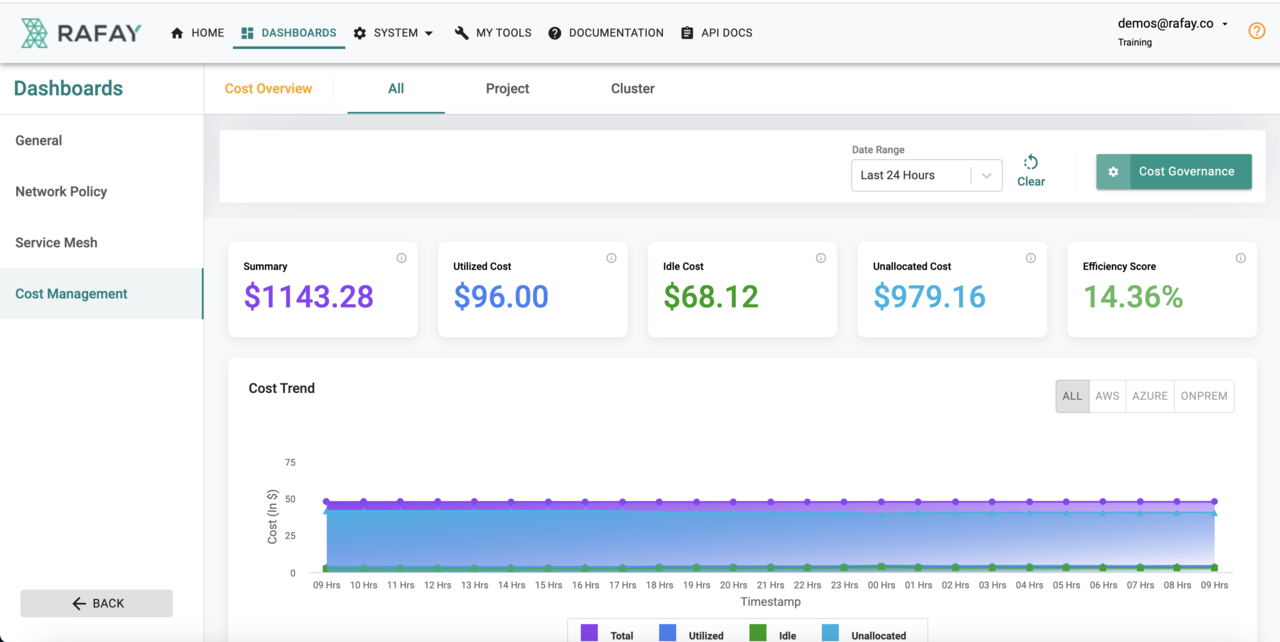
Last week, we wrapped up "hands-on enablement" on our recently released "Integrated Cost Management" service for approximately 25 technologists. Here's what the team experienced in the 60-minute lab.
1. What does it take to enable cost visibility and management for a fleet of clusters spanning Amazon EKS, Azure AKS, and on-premises clusters in data centers?
With the Rafay Kubernetes Operations Platform, you can do this literally in a "single click/step".