Choosing the Right Fractional GPU Strategy for Cloud Providers
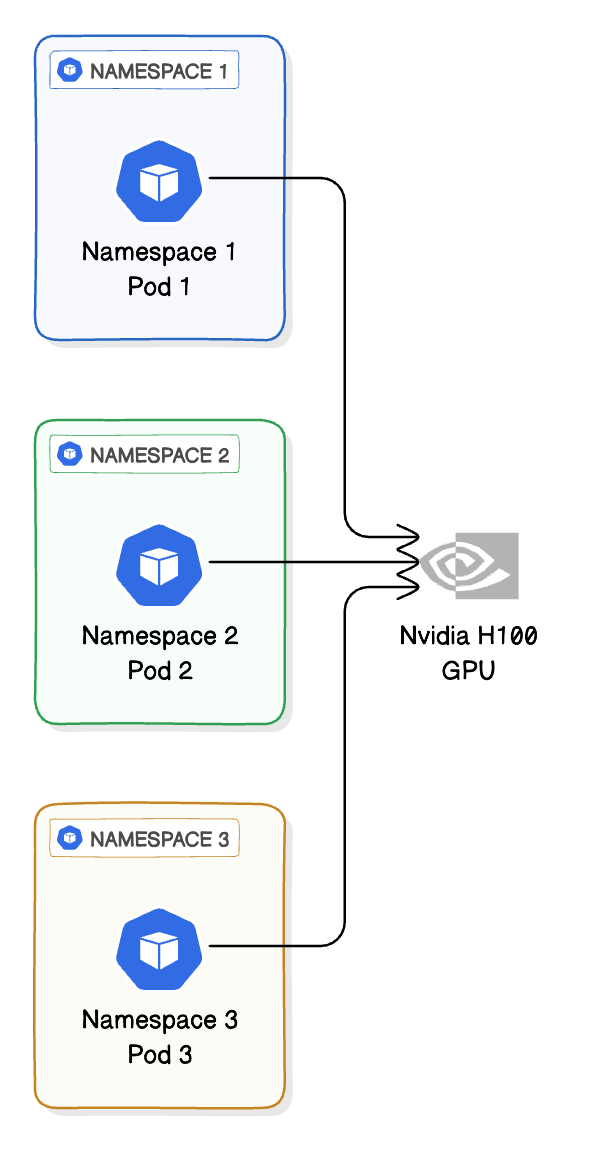
As demand for GPU-accelerated workloads soars across industries, cloud providers are under increasing pressure to offer flexible, cost-efficient, and isolated access to GPUs. While full GPU allocation remains the norm, it often leads to resource waste—especially for lightweight or intermittent workloads.
In the previous blog, we described the three primary technical approaches for fractional GPUs. In this blog, we'll explore the most viable approaches to offering fractional GPUs in a GPU-as-a-Service (GPUaaS) model, and evaluate their suitability for cloud providers serving end customers.