Why do we need Custom Schedulers for Kubernetes?¶
The Kubernetes scheduler is the brain that is responsible for assigning pods to nodes based on resource availability, constraints, and affinity/anti-affinity rules. For small to medium-sized clusters running simple stateless applications like web services or APIs, the default Kubernetes scheduler is a great fit. The default Kubernetes scheduler manages resource allocation, ensures even distribution of workloads across nodes, and supports features like node affinity, pod anti-affinity, and automatic rescheduling.
The default scheduler is extremely well-suited for long-running applications like web services, APIs, and microservices. Learn more about the scheduling framework.
Unfortunately, AI/ML workloads have very different requirements that the default scheduler cannot satisfy!
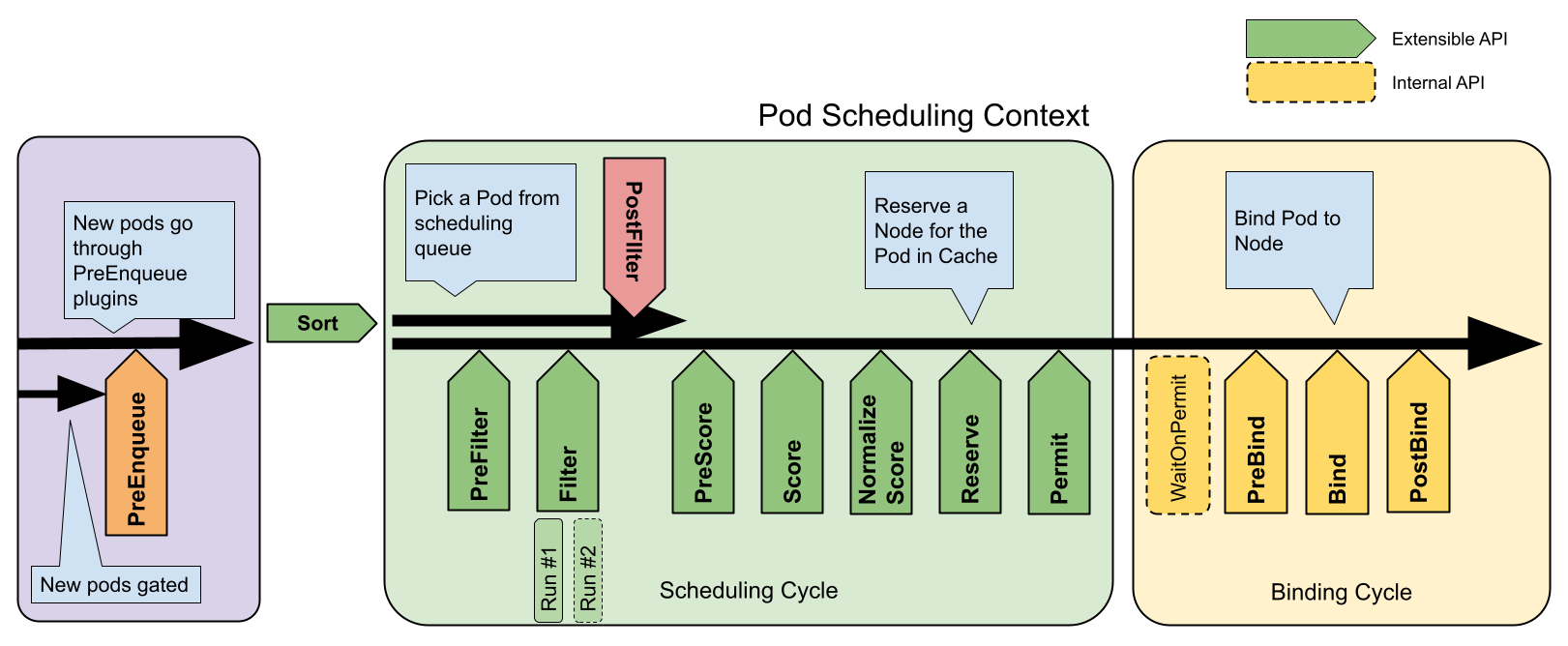
Scheduling Requirements for AI/ML¶
Let's look at this in greater detail so that we can understand it better.
1. Gang Scheduling¶
Workloads where multiple tasks must start simultaneously (e.g., distributed training in ML or HPC), gang scheduling is paramount. If some tasks start while others are pending, it will waste resources and slow down job completion.
The default Kubernetes scheduler does not support this.
2. Preemption and Backfilling¶
In environments where job priorities are important, you might want lower-priority jobs to be preempted by higher-priority ones when resources become constrained. Backfilling also allows smaller jobs to use idle resources temporarily, optimizing resource utilization.
The default Kubernetes scheduler does not support this.
3. Fair Resource Distribution¶
In organizations where multiple AI/ML teams share a Kubernetes cluster, it is critical to prevent resource hogging by a single user or application.
4. Job Dependency Management¶
Some applications require a sequence of jobs to be run in a specific order, where one job starts only after the previous one finishes. While Kubernetes native scheduler supports basic dependencies via CronJobs or init containers, complex job orchestration is not possible at this time.
5. Distributed Training Jobs¶
For distributed frameworks like Ray, Spark, or TensorFlow, tasks may need to coordinate closely across multiple nodes. A custom scheduler can ensure these tasks are placed optimally across nodes to minimize communication overhead and maximize performance.
Examples of Custom Schedulers¶
Let's look at a few popular examples of custom schedulers in the market.
Volcano¶
Volcano is a CNCF governed project. It is well suited for HPC, AI/ML, and other large-scale, batch computing workloads.
Kueue¶
Kueue is a k8s native queuing system designed to manage batch jobs and workloads.
Yunikorn¶
Yunikorn is an Apache project. This scheduler is well suited for batch jobs and long-running services.
Summary¶
In this blog, we discussed why a custom scheduler is required for specialized use cases such as distributed computing, AI/ML training etc. We also looked at a few popular custom schedulers. In the next blog, we will compare and contrast the three custom schedulers we discussed above: Volcano, Kueue and Yunikorn.
Important
Rafay's Ray as a Service offering for AI/ML uses the Volcano custom scheduler for Kubernetes.
Thanks to readers of our blog who spend time reading our product blogs and suggest ideas.
-
Free Org
Sign up for a free Org if you want to try this yourself with our Get Started guides.
-
 Live Demo
Live Demo
Schedule time with us to watch a demo in action.
-
Rafay's AI/ML Products
Learn about Rafay's offerings in AI/ML Infrastructure and Tooling
-
:simple-eventbrite:{ .middle } Upcoming Events
Meet us in-person in the Rafay booth in one of the upcoming events