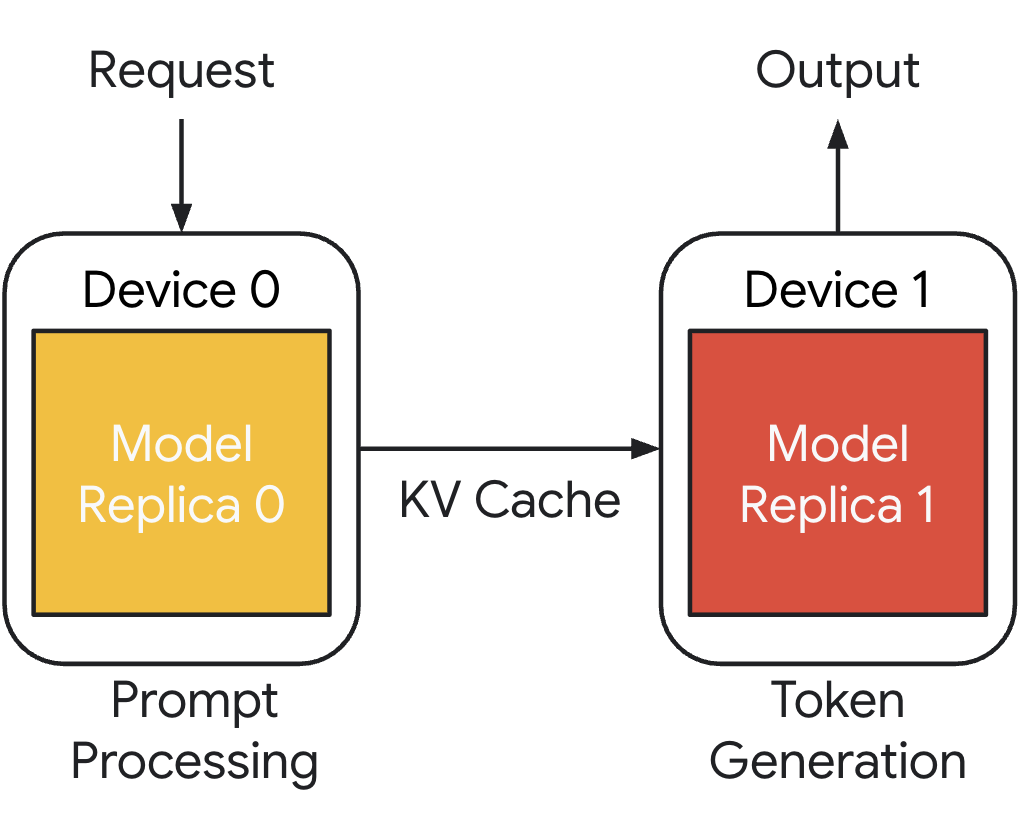
Introduction to Disaggregated Inference: Why It Matters
The explosive growth of generative AI has placed unprecedented demands on GPU infrastructure. Enterprises and GPU cloud providers are deploying large language models at scale, but the underlying inference serving architecture often can't keep up.
In this first blog post on disaggregated inference, we will discuss how it differs from traditional serving, why it matters for platform teams managing GPU infrastructure, and how the ecosystem—from NVIDIA Dynamo to open-source frameworks—is making it production-ready.