NVIDIA Dynamo: Turning Disaggregated Inference Into a Production System
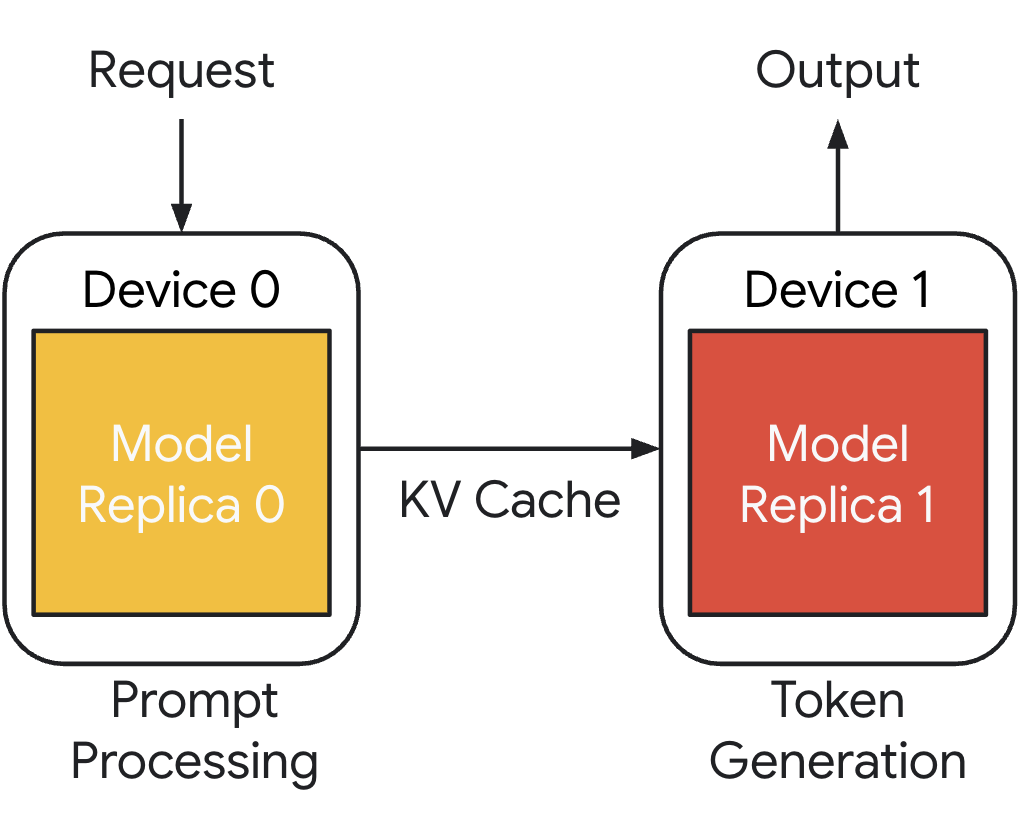
In Part 1, we covered the core idea behind disaggregated inference. That architectural split is no longer just a research pattern. Disaggregated inference changes inference from a simple “deploy a container on GPUs” exercise into a distributed system problem.
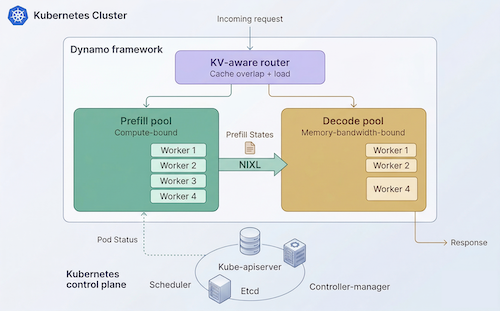
Once prefill and decode are separated, the platform has to coordinate routing, GPU-to-GPU KV cache transfer, placement, autoscaling, service discovery, and fault handling across multiple worker pools. NVIDIA Dynamo provides the distributed inference framework for this, and Kubernetes provides the control plane foundation to operate it at scale. 
In this blog post, we will review NVIDIA's Dynamo project with a focus on what it does and when it it makes sense to use it.