Why is your GPU VM slower Than Its Twin?
Picture two GPU VMs on the same bare-metal host, provisioned identically: same GPU model, same vCPU count, same memory allocation, same container image. One of them runs your inference workload 20% slower than the other — every time, consistently, with no other tenant contention and nothing wrong in the logs.
The difference isn't the GPU. It's the distance between the CPU cores feeding that GPU and the memory those cores are reading from. That distance has a name Non-Uniform Memory Access (NUMA). On modern multi-socket, multi-GPU hosts, it's one of the most common, least visible sources of inconsistent performance in GPU cloud environments.
At Rafay, we spend a lot of time thinking about how to make GPU infrastructure predictable because "predictable" is the whole point of a platform. So, we thought it is worth taking a step back and explaining what NUMA actually is, why it matters esp. once GPUs enter the picture, and what a platform needs to do about it.
This is the first part of a blog series on NUMA, how it impacts VMs esp. GPU VMs and approaches that are required to deliver great performance to GPU VMs on moden platforms.
Before NUMA
Older, simpler servers had a single memory controller feeding every core through one shared bus called Uniform Memory Access (UMA). Every core paid the same cost to reach any byte of memory. It's a clean model, and it scales fine until you try to put more cores on the chip than one memory controller and one set of physical traces can serve without slowing everything down.
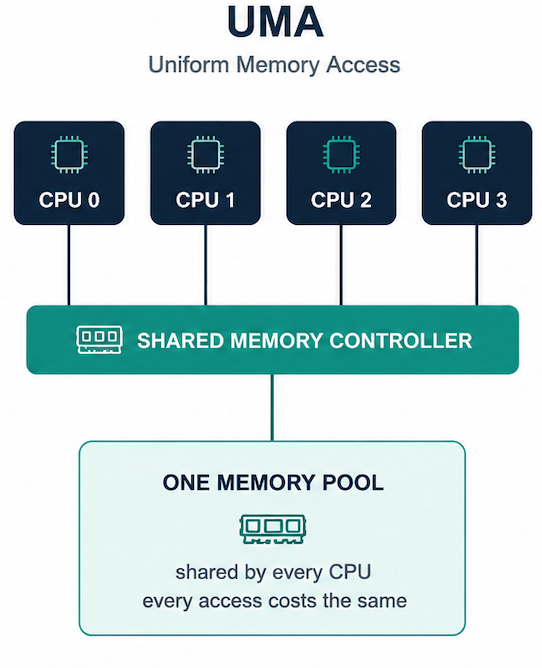
The industry's fix, dating back to big multiprocessor systems in the 1990s and arriving in mainstream x86 servers in the early 2000s, was to give each socket its own memory controller and its own slice of physical memory i.e. a NUMA "node."
Cores on that node can still reach memory anywhere in the system, but reaching memory on a different node means crossing an interconnect, and that crossing costs more than a local access, typically somewhere in the neighborhood of 1.5–3x the latency, with correspondingly lower effective bandwidth.
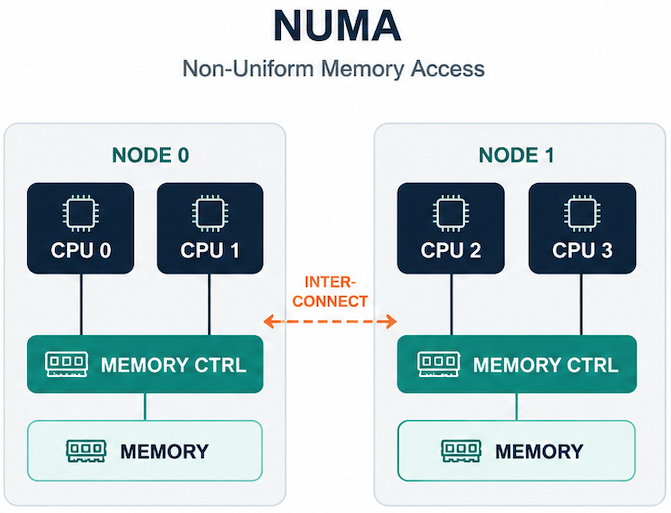
The issue is that this gap gets worse under real load. An idle-machine microbenchmark might show cross-node access at 2x the cost of local access. In reality, a busy production host, where many cores are all trying to use the same interconnect at once, can see that multiply to 4-5x, because everyone is contending for the same limited cross-node bandwidth.
This is precisely the kind of why does this get slow under load, with no obvious contention mystery that shows up on GPU-dense hosts running multiple tenants or multiple models.
Info
A modern dual-socket GPU host can easily present six, eight, or more NUMA nodes and per-node memory capacity shrinks accordingly. A workload that comfortably fit "on a node" on older hardware can now straddle two or three nodes purely because of memory-per-node math, even if its CPU footprint is small. That's a routine surprise on today's GPU-dense servers, not an edge case.
Why does this matter for GPUs?
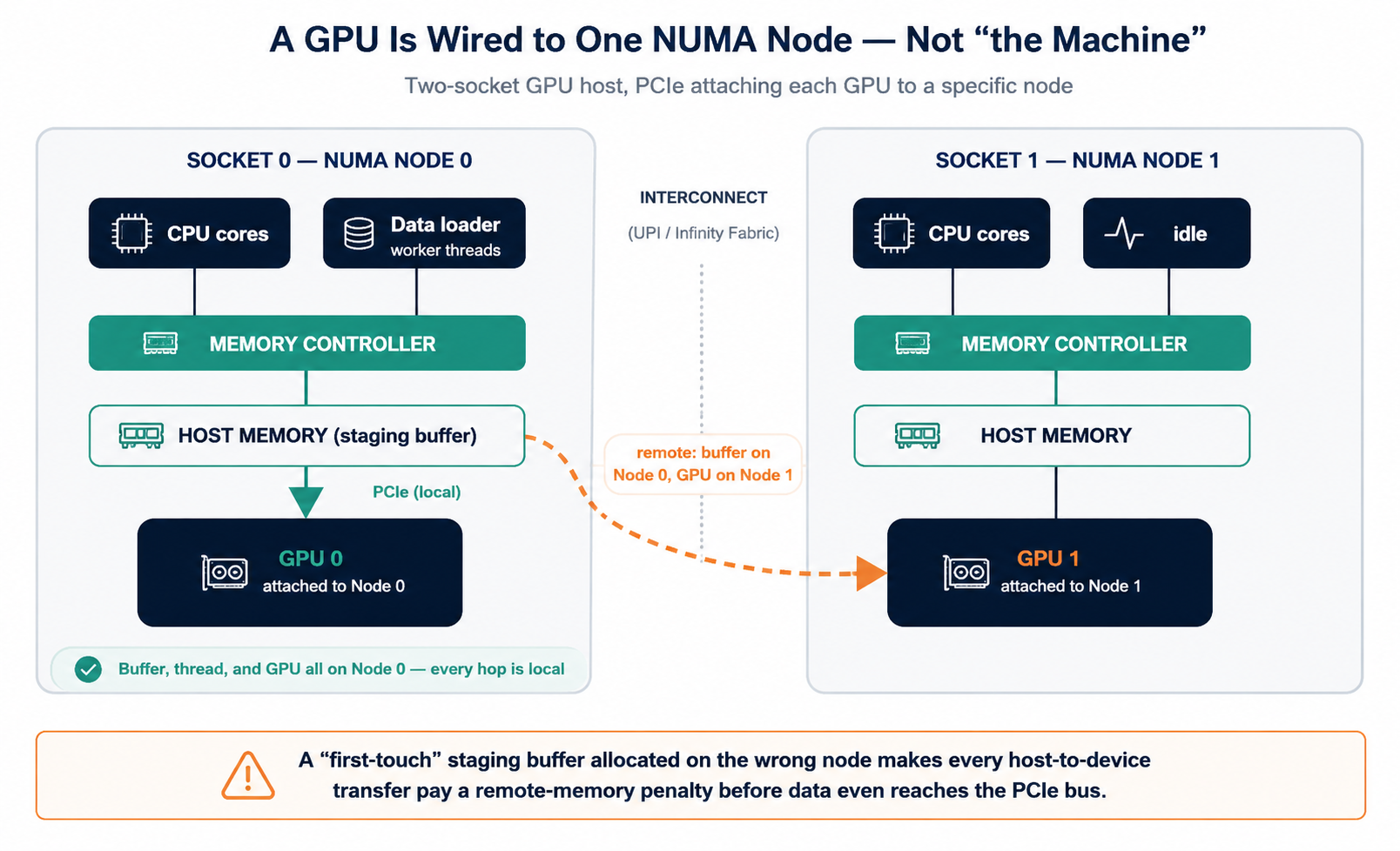
NUMA has always mattered for CPU-bound workloads. It matters more for GPU workloads, for a structural reason. A GPU is not attached "to the machine" in the abstract. It is wired via PCIe (or NVLink, for multi-GPU systems) to a specific socket, and therefore to a specific NUMA node.
That means GPU workloads inherit NUMA sensitivity on top of the usual CPU/memory affinity problem, in a few compounding ways:
1. Host-to-Device Transfer Cost
Every time data moves from host memory to GPU memory (or back), the CPU thread staging that transfer needs to be on the same NUMA node as both the GPU and the memory buffer it's reading from. If the staging buffer was allocated on the wrong node — a classic "first-touch" allocation mistake, where memory lands on whichever node happened to touch it first, not whichever node requested it — every transfer pays a remote-memory penalty before the data even reaches the PCIe bus.
2. Multi-GPU Topology
On multi-GPU hosts, GPU-to-GPU communication that has to cross a NUMA boundary (rather than staying within NVLink-connected GPUs on the same node) adds latency that shows up directly in distributed training or tensor-parallel inference throughput.
3. Data Loading and Preprocessing
CPU-side data loaders feeding a GPU need their worker threads pinned to the same node as the GPU they're feeding — otherwise the classic "GPU sits idle waiting for the next batch" pattern gets worse for reasons that have nothing to do with I/O throughput.
4. Virtualization
In a GPU VM, there are now two schedulers and two memory allocators making placement decisions about the same physical resources — the hypervisor's and the guest's — and each one only sees half the picture. If the guest doesn't know its own vNUMA topology (a common default), its kernel and any NUMA-aware application code inside it have nothing real to act on.
The hypervisor may have placed the guest's memory and vCPUs perfectly, but if the guest can't see that placement, its own optimizations can work directly against it, pinning a hot data-loader thread to a vCPU and then allocating that thread's buffers on whichever node the allocator prefers, which may not be the node the GPU sits on at all.
A Blunt Fix is Insufficient
The simplest way to flatten NUMA variance is memory interleaving. This spreads allocations round-robin across every node regardless of who's asking. It trades peak performance for consistency.
What this means is that instead of half your workload running fast and half running slow depending on placement luck, everything runs at roughly the average cost. For NUMA-oblivious software, or for genuinely memory-bandwidth-bound workloads that span the whole machine anyway, that's a reasonable trade.
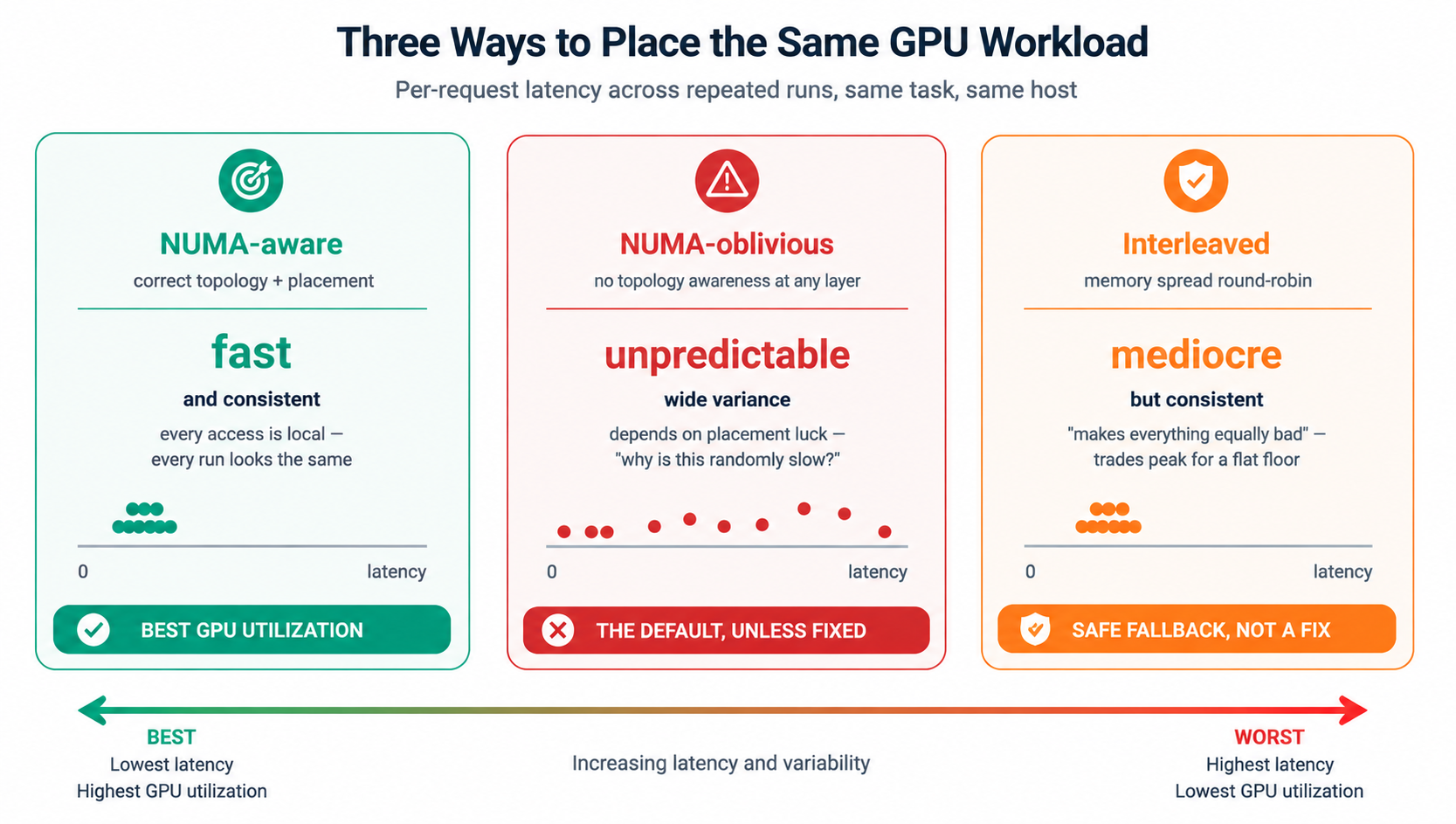
For GPU workloads, it's almost always the wrong trade. A training job or inference server that knows exactly which node its GPU lives on, and gets memory and vCPU placement that matches, can meaningfully outperform an interleaved baseline on both latency and throughput.
GPU time is the most expensive resource in the stack. Papering over placement with interleaving means leaving GPU utilization on the table to avoid doing placement correctly in the first place.
Summary
This is exactly the kind of problem that shouldn't be left to individual application teams to try and solve. It belongs at the platform layer, made automatic and topology-aware by default. This is a core part of the thinking behind how we approach GPU infrastructure at Rafay. By treating placement, isolation, and topology as first-class scheduling inputs rather than an afterthought oeprators can offer GPU capacity that behaves the same way twice, not once fast and once mysteriously slow.
In the next blog, we will introduce NVIDIA's Performance Reference Architecture for GPU VMs and describe how Rafay aligns and complies with it.